MySQL大体量业务数据表迁移方案
MySQL大体量业务数据表迁移方案
xukun大体量业务数据表迁移方案
全量+增量混合迁移
背景分析
对大体量业务数据表和归档数据表字段进行查询后,整理出所有非create_time的表如下所示:
大体量业务数据表中非create_time的表:
- hy_business_platform_log (LOG_DATE)
- ota_eol_message_log (req_time)
归档数据表中非create_time的表:
- driving_behavior_xx(create_date)
- archive_driving_behavior_xx(create_date)
由于大部分表都有create_time字段,因此全量和增量迁移都基于create_time进行数据分片,具体执行方案如下。
全量迁移:
1、数据导入:将临时存储区的全量数据迁移至新建的归档数据库。
创建迁移配置表
1
2
3
4
5
6
7
8
9
10
11CREATE TABLE migration_config (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
source_db_name VARCHAR(128) NOT NULL COMMENT '源库名',
source_table_name VARCHAR(128) NOT NULL COMMENT '源库表名',
target_db_name VARCHAR(128) NOT NULL COMMENT '归档库名',
target_table_name VARCHAR(128) NOT NULL COMMENT '归档库表名',
time_stamp VARCHAR(128) NOT NULL COMMENT '源表中时间的实际字段名,作为时间标识',
now_create_time DATETIME NOT NULL COMMENT '当前迁移的记录值,记录上次迁移的最新时间'
state VARCHAR(20) NOT NULL COMMENT '当前批次迁移状态'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
COMMENT = '迁移配置表,记录源库和归档库迁移进度';全量迁移后将归档表中最大时间记录到now_create_time中
2、数据一致性验证:执行校验脚本比对源库与归档库的数据总量。
基于行数的比对
源库查询
1
2
3
4SELECT COUNT(*) AS source_count
FROM source_db.table_name
WHERE create_time > ?
AND create_time <= ?;归档库查询
1
2
3
4SELECT COUNT(*) AS archive_count
FROM archive_db.table_name
WHERE create_time > ?
AND create_time <= ?;直接比较源库中对应表和归档库中在当前迁移范围内表的记录总数是否一致,加上时间范围确保不会因时间差导致的数据变化
基于主键范围随机抽样
首先获取主键范围(min_id,max_id)
1
2
3
4SELECT MIN(id) AS min_id, MAX(id) AS max_id
FROM source_db.table_name
WHERE create_time > ?
AND create_time <= ?;按百分百抽样1%或固定1000-5000条在(min_id,max_id)范围内的随机数并存储
遍历存储的随机数,校验是否存在,若不存在则获取到id大于等于r的最近一条记录:
可以存储到redis中使用set进行去重并且存储去重后的数据
1
2
3
4SELECT * FROM archive_db.table_name
WHERE id >= r
ORDER BY id ASC
LIMIT 1;将得到的样本数据通过关键字段,如 id、col1、col2 等进行摘要计算,用MD5算法拼接字段后生成摘要信息
1
2
3SELECT id, MD5(CONCAT_WS(',', id, col1, col2)) AS row_md5
FROM source_db.table_name
WHERE id = @ids;将两个库返回的md5值进行比对
3、数据删除:验证完成通过之后,删除归档库中一年之内的业务数据,同时删除源库中超过一年的业务数据。
对于归档库和源库中数据都使用分批方式进行删除
删除归档库中一年之内的业务数据
确定删除的具体开始时间后进行遍历删除
1
2
3
4
5
6
7SET @rows_deleted = 1;
WHILE @rows_deleted > 0 DO
DELETE FROM archive_db.table_name
WHERE create_time >= DATE_SUB('2025-02-25 00:00:00', INTERVAL 1 YEAR)
LIMIT 10000;
SET @rows_deleted = ROW_COUNT();
END WHILE;每次删除10000条或其他数量,循环执行直到没有可删记录
使用ROW_COUNT() 检测本次删除多少行,如果是0,说明删完了
删除源库中超过一年的业务数据,同上
1
2
3
4
5
6
7SET @rows_deleted = 1;
WHILE @rows_deleted > 0 DO
DELETE FROM source_db.table_name
WHERE create_time < DATE_SUB('2025-02-25 00:00:00', INTERVAL 1 YEAR)
LIMIT 10000;
SET @rows_deleted = ROW_COUNT();
END WHILE;可能存在问题:
- createTime字段名不统一的需要单独分析
- 旧库中的某些表在新库中找不到,需要手动导出建表语句并且建表再进行迁移
增量迁移:
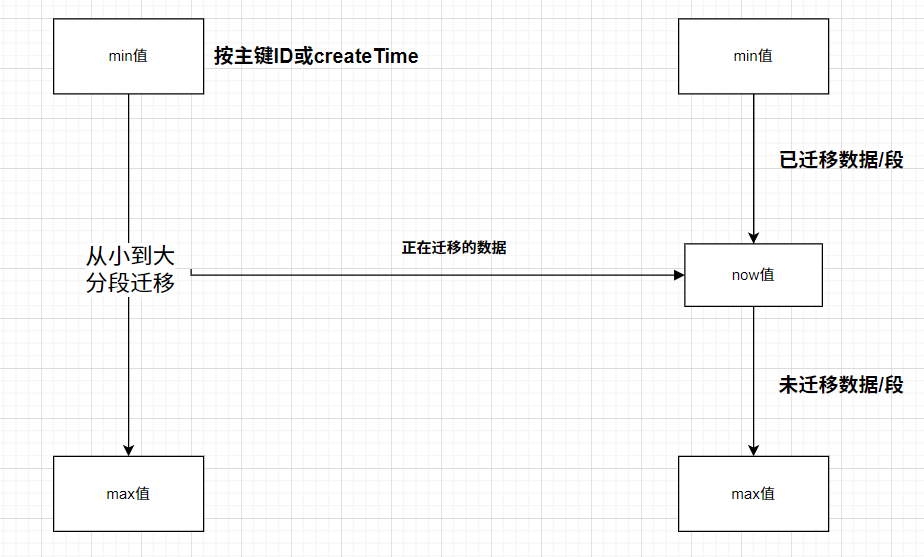
1、编写任务调度定时任务的程序,通过主键ID或create_time创建时间确定增量迁移范围进行数据分片,并通过数据分片分批提取数据进行迁移。
流程图

每季度1号凌晨0点启动迁移,通过create_time按小时分批迁移
伪代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31//从迁移配置表中取now_create_time为起始时间
Timestamp now_create_time = getMigrationConfig();
//设置每季度1号凌晨0点开始迁移
LocalDate today = LocalDate.now();
int currentMonth = today.getMonthValue();
//当前季度的起始月份(1、4、7、10)
int quarterStartMonth = ((currentMonth - 1) / 3) * 3 + 1;
LocalDate quarterStartDate = LocalDate.of(today.getYear(), quarterStartMonth, 1);
LocalDateTime targetDateTime = quarterStartDate.atStartOfDay();
Timestamp targetTime = Timestamp.valueOf(targetDateTime);
//循环遍历数据,按小时分片
Timestamp currentStart = now_create_time;
while (currentStart.before(targetTime)) {
Timestamp currentEnd = new Timestamp(Math.min(currentStart.getTime() + 3600 * 1000L, targetTime.getTime()));
//分批迁移当前时间段内的数据
while (true) {
List<Record> batch = fetchDataByCreateTime(currentStart, currentEnd, batchSize);
if (batch.isEmpty()) {
break;
}
insertBatchIntoTarget(batch);
//设置currentStart为最后记录的create_time
currentStart = batch.get(batch.size() - 1).getCreateTime();
}
//当前小时分片结束,更新迁移配置表中的now_create_time为currentEnd
updateMigrationConfig(currentEnd);
//下一个小时分片
currentStart = currentEnd;
}
2、制定数据校验机制,对比源库时间窗口内的数据总量与归档库新增量,进行验证。
对比从上次迁移的最新now_create_time到当日截止时间内,源库和归档库中记录的总行数是否一致,判断数据迁移是否成功,确保没有数据遗漏或重复
1
2
3SELECT COUNT(*) AS cnt1
FROM source_db.table_name
WHERE create_time > migration_config.now_create_time AND create_time <= ?;1
2
3SELECT COUNT(*) AS cnt2
FROM archive_db.table_name
WHERE create_time > migration_config.now_create_time AND create_time <= ?;
3、验证通过后,将源库上的表已迁移数据进行删除,并释放空间。
假设每次删除10000条,使用循环进行删除,直至本次删除时间范围内的数据全部删除完毕
1
2
3DELETE FROM source_db.table_name
WHERE create_time > migration_config.now_create_time AND create_time <= ?
LIMIT 10000;
4、增量迁移完成,邮件通知
5、紧急回迁应急方案,按预设时间范围执行数据分段恢复,确保紧急恢复时效性
当增量迁移过程中或迁移后发现数据异常,比如迁移数据不一致、迁移过程中断等,需要进行紧急回签
从迁移配置表的now_create_time和state中找到受影响的时间段,按小时进行分批操作
首先从源库中删除该时间范围内的数据,确保没有错误数据
1
DELETE FROM source_db.table_name WHERE create_time > ? AND create_time <= ?;
每批操作采用事务控制,确保回迁过程中出现异常时能回滚
记录每批次恢复的数据量和操作日志
回迁完成后,通过行数比对,验证数据一致性